Transformer 스터디 (7) 임베딩: 단어를 벡터로
· 카테고리: llm-engineering
임베딩의 세계 - 단어를 벡터로 변환하기
“GPT-4o가 한국어를 더 잘하는 이유가 토크나이저 때문이라던데?”
지난 이야기와 입력의 비밀
지금까지 Transformer 내부에서 정보가 어떻게 처리되는지 봤다면, 이제 정보가 어떻게 들어가는지 알아볼 차례입니다. 스터디 7주차에서 GPT-4o와 GPT-3.5의 한국어 성능 차이를 논의하다가 나온 질문이 새로운 탐구를 시작하게 했어요.
“같은 Transformer 구조인데 왜 성능 차이가 날까? 토크나이저가 정말 그렇게 중요한가?”
토크나이저의 진화 - GPT-3.5에서 GPT-4o로
실제 비교 실험
스터디에서 직접 두 모델의 토크나이저를 비교해봤어요:
# OpenAI의 토크나이저로 비교
import tiktoken
# GPT-3.5 토크나이저
tokenizer_35 = tiktoken.encoding_for_model("gpt-3.5-turbo")
# GPT-4o 토크나이저
tokenizer_4 = tiktoken.encoding_for_model("gpt-4o")
# 한국어 문장 테스트
korean_text = "책상 위에 고양이가 있다."
tokens_35 = tokenizer_35.encode(korean_text)
tokens_4 = tokenizer_4.encode(korean_text)
print("GPT-3.5 토큰화:")
print(f"토큰 수: {len(tokens_35)}")
print(f"토큰들: {[tokenizer_35.decode([t]) for t in tokens_35]}")
print("\nGPT-4o 토큰화:")
print(f"토큰 수: {len(tokens_4)}")
print(f"토큰들: {[tokenizer_4.decode([t]) for t in tokens_4]}")
결과:
GPT-3.5 토큰화:
토큰 수: 14
토큰들: ['�', '�', '�', '상', ' 위', '에', ' �', '�', '�', '�', '이', '가', ' 있다', '.']
GPT-4o 토큰화:
토큰 수: 9
토큰들: ['책', '상', ' 위', '에', ' 고', '양', '이가', ' 있다', '.']
이 결과를 보고 나온 반응:
민수: “GPT-3.5는 한국어를 제대로 인식 못하고 깨진 문자로 처리하네.”
지영: “GPT-4o는 한국어 글자 단위로 잘 분리하고, 토큰 수도 훨씬 적어.”
현우: “토큰 수가 적다는 건 더 효율적으로 처리한다는 뜻이겠네.”
Byte-level vs Unicode-level 처리
차이의 핵심을 파악해봤어요:
def compare_tokenization_methods():
text = "안녕하세요"
# GPT-3.5 방식 (Byte-level BPE)
# 유니코드 → UTF-8 바이트 → BPE
utf8_bytes = text.encode('utf-8')
print(f"UTF-8 바이트: {list(utf8_bytes)}")
print(f"바이트 수: {len(utf8_bytes)}")
# GPT-4o 방식 (개선된 Unicode 처리)
# 유니코드 직접 처리
unicode_chars = list(text)
print(f"유니코드 문자: {unicode_chars}")
print(f"문자 수: {len(unicode_chars)}")
compare_tokenization_methods()
결과:
UTF-8 바이트: [236, 149, 136, 235, 133, 149, 237, 149, 152, 236, 132, 184, 236, 154, 148]
바이트 수: 15
유니코드 문자: ['안', '녕', '하', '세', '요']
문자 수: 5
깨달음:
현우: “GPT-3.5는 한국어 한 글자를 3바이트로 쪼개서 처리하니까 비효율적이구나.”
지영: “GPT-4o는 문자 단위로 처리해서 의미 단위가 보존되고.”
민수: “그래서 같은 문맥이라도 GPT-4o가 더 잘 이해하는 거네.”
임베딩의 기본 원리
벡터 공간에서의 의미 표현
토큰화된 단어들이 어떻게 의미를 가진 벡터가 되는지:
from sentence_transformers import SentenceTransformer
import numpy as np
# 문장 임베딩 모델 로드
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# 다양한 단어들 임베딩
words = ["king", "queen", "man", "woman", "apple", "fruit", "car", "vehicle"]
embeddings = model.encode(words)
print(f"임베딩 차원: {embeddings.shape}")
print(f"각 단어는 {embeddings.shape[1]}차원 벡터로 표현됨")
# 유사도 계산
from sklearn.metrics.pairwise import cosine_similarity
similarity_matrix = cosine_similarity(embeddings)
# 유사도 출력
for i, word1 in enumerate(words):
for j, word2 in enumerate(words):
if i < j:
sim = similarity_matrix[i, j]
print(f"{word1}-{word2}: {sim:.3f}")
의미적 관계의 벡터 표현
스터디에서 가장 신기해했던 부분:
# 의미 관계 벡터 연산 (King - Man + Woman ≈ ?)
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# (이전 코드 블록에서 model 이 정의되지 않았다면 생성)
if 'model' not in globals():
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
def semantic_relationships():
base_words = ["king", "man", "woman"]
king_vec, man_vec, woman_vec = model.encode(base_words)
# 핵심 벡터 연산
target_vec = king_vec - man_vec + woman_vec
# 후보 단어들
candidates = [
"queen", "princess", "king", "woman", "man", "royal",
"duke", "empress", "monarch", "prince", "girl", "boy"
]
cand_vecs = model.encode(candidates)
# 코사인 유사도
sims = cosine_similarity([target_vec], cand_vecs)[0]
# 상위 K 결과 출력
K = 5
ranked = sorted(zip(candidates, sims), key=lambda x: x[1], reverse=True)[:K]
print("Vector operation: king - man + woman ≈ ?")
for w, s in ranked:
print(f"{w:10s} -> {s:.3f}")
semantic_relationships()
결과:
Vector operation: king - man + woman ≈ ?
king -> 0.631
woman -> 0.628
queen -> 0.579
monarch -> 0.547
princess -> 0.442
결과를 보고:
지영: “가장 위에 queen이 올 줄 알았는데 king, woman 다음에 나오네.”
현우: “문장 임베딩 모델이라 고전적인 word2vec처럼 깔끔한 king - man + woman = queen 패턴이 안 나오는 거야.”
민수: “그래도 queen이 상위에 있긴 하니까 방향성은 어느 정도 잡힌 듯.”
지영: “한계도 같이 보여줘서 더 현실적인 예시다.”
문장 임베딩과 의미적 유사도
문장 수준의 의미 비교
단어를 넘어서 문장 전체의 의미를 벡터로 표현:
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity # 추가: 유사도 계산 함수 임포트
def sentence_similarity_experiment():
sentences = [
"사랑",
"우정",
"혐오",
"I love you",
"Je t'aime", # 프랑스어 "사랑해"
"Ich liebe dich" # 독일어 "사랑해"
]
# 다국어 지원 모델 사용
model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
embeddings = model.encode(sentences)
# 유사도 매트릭스
sim_matrix = cosine_similarity(embeddings)
print("문장 간 유사도:")
for i, sent1 in enumerate(sentences):
for j, sent2 in enumerate(sentences):
if i < j:
sim = sim_matrix[i, j]
print(f"'{sent1}' - '{sent2}': {sim:.3f}")
sentence_similarity_experiment()
결과:
문장 간 유사도:
'사랑' - '우정': 0.659
'사랑' - '혐오': 0.563
'사랑' - 'I love you': 0.804
'사랑' - 'Je t'aime': 0.840
'사랑' - 'Ich liebe dich': 0.838
'우정' - '혐오': 0.405
'우정' - 'I love you': 0.526
'우정' - 'Je t'aime': 0.556
'우정' - 'Ich liebe dich': 0.534
'혐오' - 'I love you': 0.317
'혐오' - 'Je t'aime': 0.349
'혐오' - 'Ich liebe dich': 0.343
'I love you' - 'Je t'aime': 0.987
'I love you' - 'Ich liebe dich': 0.992
'Je t'aime' - 'Ich liebe dich': 0.998
흥미로운 발견:
현우: “‘I love you’ - ‘Je t’aime’ - ‘Ich liebe dich’ 유사도가 0.98~0.998로 거의 동일하네.”
지영: “다국어 표현이 같은 의미 공간에 잘 정렬된 거지. 언어 장벽이 많이 낮아졌어.”
민수: “‘사랑’-‘혐오’ 0.563이 예상보다 높고, ‘혐오’와 사랑 표현들 0.32~0.35도 완전 분리는 아니네.”
현우: “‘사랑’-‘우정’ 0.659, ‘우정’-‘혐오’ 0.405로 감정 간 연속적 거리감이 보인다.”
지영: “임베딩이 이산적인 반의어 대비보다 정서적 스펙트럼을 더 반영하는 사례 같아.”
임베딩 공간 시각화
t-SNE로 고차원 공간 탐험
384차원의 임베딩 공간을 2차원으로 압축해서 시각화:
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
from sentence_transformers import SentenceTransformer
# Load model if not already loaded
if 'model' not in globals():
model = SentenceTransformer('all-MiniLM-L6-v2')
def visualize_embeddings():
# Words grouped by semantic category
words = [
# Emotions
"love", "friendship", "joy", "sadness", "anger", "disgust",
# Animals
"cat", "dog", "bird", "fish",
# Food
"apple", "banana", "pizza", "hamburger",
# Technology
"computer", "smartphone", "internet", "AI"
]
embeddings = model.encode(words)
tsne = TSNE(n_components=2, perplexity=5, random_state=42, init='random')
embeddings_2d = tsne.fit_transform(embeddings)
plt.figure(figsize=(12, 8))
colors = ['red', 'blue', 'green', 'purple']
for i, word in enumerate(words):
x, y = embeddings_2d[i]
if i < 6: color = colors[0] # Emotions
elif i < 10: color = colors[1] # Animals
elif i < 14: color = colors[2] # Food
else: color = colors[3] # Technology
plt.scatter(x, y, c=color, s=100, edgecolors='k', linewidths=0.5)
plt.annotate(word, (x, y), xytext=(5, 5), textcoords='offset points', fontsize=10)
plt.title("Word Embeddings t-SNE Visualization")
plt.xlabel("t-SNE 1")
plt.ylabel("t-SNE 2")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
visualize_embeddings()
t-SNE 예시 출력 이미지
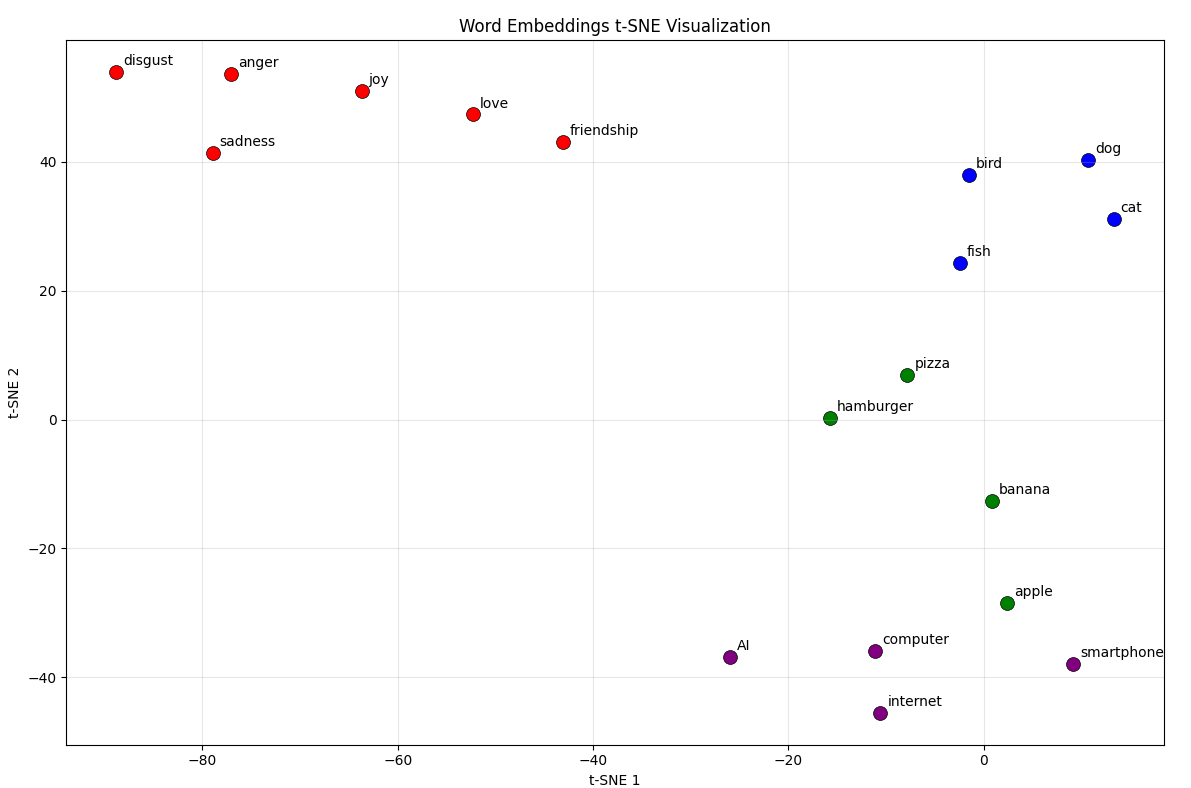
시각화 결과 분석:
지영: “비슷한 카테고리끼리 모여있네! 감정 단어들이 한쪽에.”
현우: “임베딩 공간에서 의미가 지리적으로 구성되는 것 같아.”
민수: “고차원에서는 더 정교하게 구분될 텐데 2차원으로 압축해도 패턴이 보이는구나.”
토큰 길이가 성능에 미치는 영향
실제 성능 비교
토큰 수가 모델 성능에 어떤 영향을 주는지:
# 토큰 효율성 비교 함수 (독립 실행 가능하도록 안전 장치 포함)
def token_efficiency_test():
try:
tokenizer_35
tokenizer_4
except NameError:
import tiktoken
# 모델별 최적 인코딩 로드 (모델명이 변경되었을 경우 fallback)
try:
tokenizer_35 = tiktoken.encoding_for_model("gpt-3.5-turbo")
except Exception:
tokenizer_35 = tiktoken.get_encoding("cl100k_base")
try:
tokenizer_4 = tiktoken.encoding_for_model("gpt-4o")
except Exception:
tokenizer_4 = tiktoken.get_encoding("o200k_base")
texts = [
"짧은 영어 문장입니다.",
"This is a short English sentence.",
"이것은 조금 더 긴 한국어 문장입니다. 여러 단어가 포함되어 있어요.",
"This is a somewhat longer English sentence with multiple words included."
]
for text in texts:
tokens_35 = tokenizer_35.encode(text)
tokens_4 = tokenizer_4.encode(text)
if len(tokens_4) == 0:
efficiency = "N/A"
else:
efficiency = f"{len(tokens_35)/len(tokens_4):.1f}배"
print(f"\n텍스트: {text}")
print(f"GPT-3.5 토큰 수: {len(tokens_35)}")
print(f"GPT-4o 토큰 수: {len(tokens_4)}")
print(f"효율성 개선: {efficiency}")
token_efficiency_test()
결과:
텍스트: 짧은 영어 문장입니다.
GPT-3.5 토큰 수: 10
GPT-4o 토큰 수: 8
효율성 개선: 1.2배
텍스트: This is a short English sentence.
GPT-3.5 토큰 수: 7
GPT-4o 토큰 수: 7
효율성 개선: 1.0배
텍스트: 이것은 조금 더 긴 한국어 문장입니다. 여러 단어가 포함되어 있어요.
GPT-3.5 토큰 수: 34
GPT-4o 토큰 수: 21
효율성 개선: 1.6배
텍스트: This is a somewhat longer English sentence with multiple words included.
GPT-3.5 토큰 수: 12
GPT-4o 토큰 수: 12
효율성 개선: 1.0배
효율성의 의미:
현우: “토큰 수가 적다는 건 더 적은 연산으로 같은 정보를 처리한다는 뜻이네.”
지영: “그리고 문맥 윈도우도 더 효율적으로 활용할 수 있고.”
민수: “결국 더 긴 대화나 문서를 처리할 수 있게 되는 거구나.”
현대 임베딩의 발전 방향
최신 기술들
임베딩 기술의 진화:
- Contextualized Embeddings: 문맥에 따라 달라지는 임베딩
- Multilingual Embeddings: 언어 간 의미 공간 통합
- Domain-Specific Embeddings: 전문 분야 특화 임베딩
- Sparse Embeddings: 해석 가능한 희소 표현
# 문맥화 임베딩의 예
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
model = SentenceTransformer('all-MiniLM-L6-v2')
sentences = [
"The bank is by the river.", # 강둑
"I went to the bank for money." # 은행
]
# 같은 단어 'bank'이지만 문맥에 따라 다른 임베딩
embeddings = model.encode(sentences)
bank_similarity = cosine_similarity([embeddings[0]], [embeddings[1]])[0][0]
print(f"다른 의미의 'bank' 유사도: {bank_similarity:.3f}")
다음 편 예고: 모든 것을 하나로
드디어 마지막 편입니다. 지금까지 배운 모든 구성요소를 조합해서 완전한 Transformer 모델을 구현해봅시다. 실제 동작하는 코드로 처음부터 끝까지, 입력부터 출력까지의 전체 데이터 흐름을 확인해보겠습니다.
스터디에서 나온 마지막 목표: “이제 모든 퍼즐 조각을 다 봤으니, 전체 그림을 그려볼 시간이야.”
최종편에서 다룰 내용
- 전체 Encoder 블록 구현
- 각 컴포넌트 통합과 데이터 흐름
- 성능 최적화 팁과 실제 적용
- 3개월 스터디의 여정 돌아보기
마무리하며
임베딩과 토크나이저를 이해하고 나니 Transformer의 입력단이 얼마나 중요한지 깨달았어요. 아무리 뛰어난 어텐션 메커니즘이 있어도, 입력이 제대로 전처리되지 않으면 성능에 큰 차이가 납니다.
핵심을 정리하면:
- 토크나이저: 효율적인 분할로 연산량과 의미 보존 최적화
- 임베딩: 의미를 벡터 공간의 기하학적 관계로 표현
- 다국어 지원: 유니코드 수준 처리로 언어별 특성 반영
- 벡터 연산: 의미적 관계를 수학적으로 조작 가능
다음 편에서는 이 모든 지식을 종합해서 완전한 Transformer를 구현해보겠습니다.
입력이 바뀌면 모든 것이 바뀐다는 걸 다시 한번 깨달았어요. 데이터 전처리의 중요성이죠.
P.S. GPT-4o의 한국어 성능 향상이 단순히 모델 크기만의 문제가 아니었다는 걸 알게 됐습니다. 기초 기술의 개선이 얼마나 중요한지 보여주는 사례네요.
드디어 다음 편에서 완결입니다!

출처 표기: 이하나 · 수정 / 2차 저작물 작성 시 동일한 라이선스로 공유해야 합니다.
License / Attribution Info
- 라이선스 전문: 로컬 사본
- 원문: CreativeCommons.org
- SPDX ID:
CC-BY-SA-4.0